
Vector向量
Vector底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”。比如,indexOf方法就增加了synchronized同步标记。
如何选用Arraylis、LinkedList、Vector?
- 1.需要线程安全时,用Vector.
- 2.不存在线程安全问题时,并且查找较多用ArrayList(一般使用这个)
- 3.不存在线程安全问题时,增加或删除元素较多用LinkedList.
Map接口
Map就是用来存储“键(key)-值(value)对”的。Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复
Map接口的实现类有HashMap、TreeMap、HashTable、Properties等。
Map的常用方法
1 | package cn.yishan.collection; |
Map的常用方法2
1 | package cn.yishan.collection; |
HashMap的底层实现
HashMap底层实现采用了哈希表,这是一种非常重要的数据结构
哈希表的基本结构就是“数组+链表”
数据结构中由数组和链表来实现对数据的存储,各有特点
- 1.数组:占用空间连续。寻址容易,查询速度快。但是,增加和删除效率非常低。
- 2.链表:占用空间不连续。寻址困难,查询速度慢。但是,增加和删除效率非常高。
哈希表 结合了数组和链表的优点(即查询快,增删效率也高)。哈希表的本质就是“数组+链表”
1 | transient Node<K,V>[] table; |
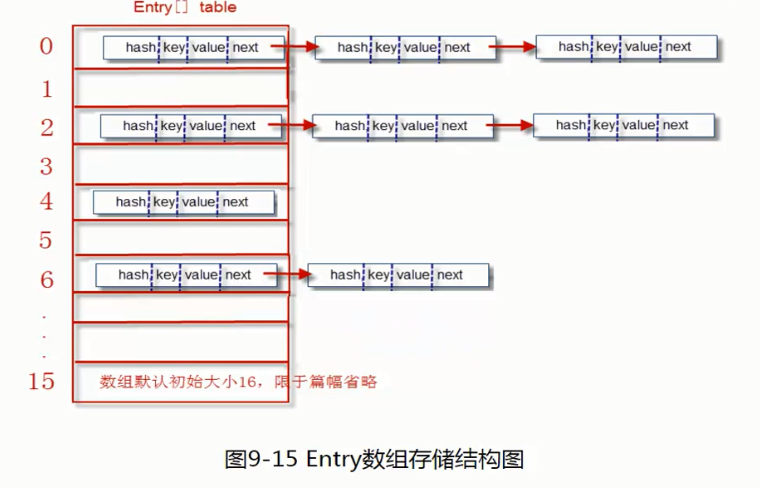
其中的 Node<K,V>[] table 就是HashMap的核心数组结构,我们也称之为“位桶数组”
1 | static class Node<K,V> implements Map.Entry<K,V> { |
一个Node对象存储了:
- 1.key:键对象 value:值对象
- 2.next:下一个节点
- 3.hash:键对象的hash值
每一个Node对象就是一个单向链表结构,即:

Node[]数组的结构(这也是HashMap的结构)
存储数据过程
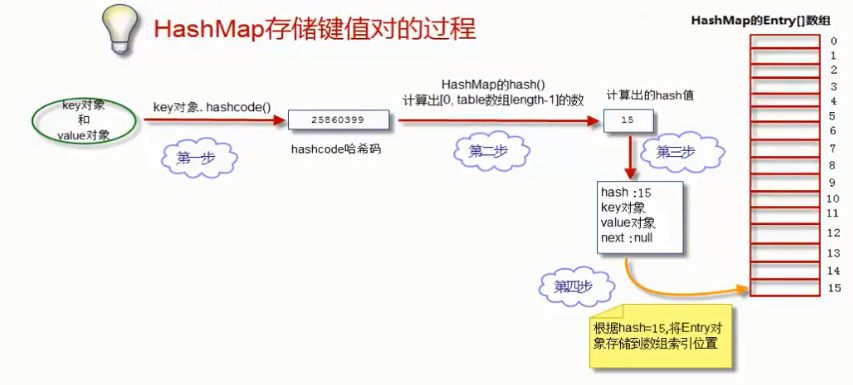
目的是将“key-value两个对象”成对存放到HashMap的Node[]数组中
1.获得key对象的hashcode,首先调用key对象的hashcode()方法,获得hashcode.
2.根据hashcode计算出hash值 (要求在[0,数组长度-1]区间),hashcode是一个整数,我们需要将它转化成[0,数组长度-1]的范围。我们要求转化后的hash值尽量均匀的分布在[0,数组长度-1]这个区间,减少“hash冲突”
3.一种极端简单和低下的算法:hash值 = hashcode/hashcode,hash值永远都是1,就行成了一个非常长的链表,HashMap也退化成了一个“链表”,相反,也会退化成为一个“数组”
4.一种简单和常用的算法是(相除取余算法):可以让hash值均匀的分布在[0,数组长度-1]的区间。早期HashTable采用这种算法,但是由于使用了“除法”,效率低下。
5.JDK改进了算法。首先约定数组长度必须为2的整数幂,这样采用位运算即可实现取余的效果:hash值 = hashcode & (数组长度-1)
JDK8中,扩容两次后,也就是数组长度达到64时,并且链表长度大于8时,链表就转换为了红黑树,这样子又大大提高了查找的效率
取数据过程get(key)
- 1.获得key的hashcode,通过hash()散列算法得到hash值,进而定位到数组的位置
- 2.在链表上挨个比较key对象。调用equal()方法,将key对象和链表上所有节点的key对象进行比较,知道碰到返回true的节点对象为止。
- 3.返回equal()为true的节点对象的value对象
java中规定,两个内容相同(euqals()为true)的对象必须具有相等的hashcode。因为如果equals()为true而两个对象的hashcode不同;那在整个存储过程中就发生了悖论。