
ElasticSearch
简称是ES
作用:用来进行搜索的
搜索的分类:
1、全网搜索:搜索互联网上所有的内容。常见的产品:百度、谷歌
2、站内搜索:搜索本网站内部的资源。常见的产品:淘宝、天猫、京东
上述搜索是怎么实现的呢?
我们想法:把数据存储到mysql数据库中,然后通过select语句进行查询即可。
但是上述的搜索功能肯定不是基于mysql数据库进行实现的,为什么?因为mysql数据库在搜索的时候是存在一定的问题。
1 mysql搜索存在的问题
存在的问题:
1、效率低
当数据量是小于100万条的时候,搜索效率还可以满足企业的要求。当数据库超过100w条以后,并且小于1000w条,可以通过一些技术手段来提高搜索效率。常见的技术手段:索引、分库分表。但是当我们在进行查询的时候,我们往往需要进行模糊查询:SELECT * FROM tb_goods where good_name like ‘%华为手机%’。当左侧存在%的时候,索引会失效。那么在进行查询的时候使用的还是全表扫描。
当数据量超过了1000w条,通过加索引以及分库分表来提升搜索效率,起到的作用就是微乎其微。
2、搜索结果不全面(功能弱)
需求:当用户输入一个关键字:华为手机,想要都是的结果是:只要商品的名称中包含了华为或者手机都需要搜索到。
实现能否使用mysql进行实现呢?
sql语句:SELECT * FROM tb_goods where good_name like ‘%华为手机%’,要求”华为手机”必须在一起才可以搜索到。
怎么解决?使用ES
2 倒排索引
在使用ES进行数据存储的时候,首先就需要对数据进行分词(term)。
正向索引:在索引表中记录的是文档的id和文档中出现的词的对应关系。

采用正向索引在进行搜索的时候使用的就是全表扫描,当数据量较大的时候搜索效率就较低。
倒排(反向)索引:建立数据的分词结果和数据id之间的对应关系。
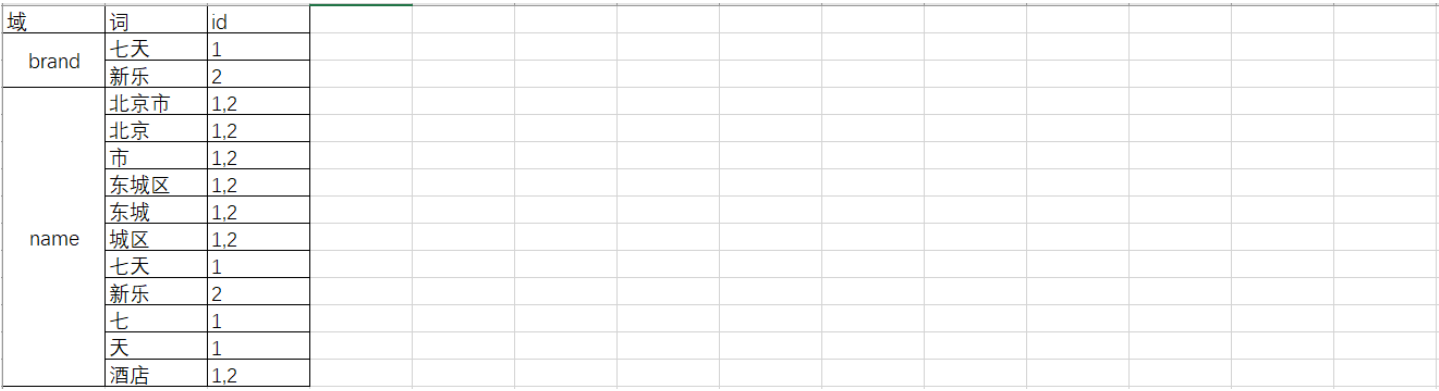
后期再进行搜索的时候,首先需要对搜索的关键字进行分词,然后根据这个词从倒排(反向)索引表中找对应的数据的id,然后根据id在找到对应的数据。
ES解决数据库查询功能弱:通过对数据进行分词来解决
ES解决数据库查询效率低:对分词的结构进行排序,然后进行了一个树形结构,提高了查询效率
3 ES的特点
ES特点:
1、ElasticSearch是一个基于Lucene的搜索服务器(Lucene是一个搜索工具包)
2、基于Lucene的搜索服务器种类:Solr , ElasticSearch(实时性搜索效率高于solr)
3、是一个分布式、高扩展、高实时的搜索与数据分析引擎
4、基于RESTful web接口

ES和mysql区别:
1、mysql数据库中是支持事务,在ES中是不支持事务的
2、mysql数据库是存在外键的,在ES中不存储
3、mysql主要的作用是进行数据的存储,而ES主要的主要就是进行搜索

4 ES和kibana安装
参考安装文档。
5 ES索引库结构
ES索引库的结构和mysql数据库的结构是很类似的:

在ES7.x之前其实还存在一个结构:type(类型),在7.X之后把type的概念进行弱化。
6 Restful风格
Restful是一种接口定义风格(把请求参数作为请求路径的一部分)。
通过不同的请求方式来区分用户的操作:
POST:新增(添加)资源
GET:获取资源
PUT:更新资源
DELETE:删除资源
7 索引操作
Postman操作索引:
- 新增
1 | PUT http://ip:端口/索引名称 |
- 查询
1 | GET http://ip:端口/索引名称 # 查询单个索引信息 |
- 删除索引
1 | DELETE http://ip:端口/索引名称 |
- 关闭、打开索引(了解)
1 | POST http://ip:端口/索引名称/_close |
8 映射操作
8.1 数据类型
映射就是定义表结构,表又是由字段(域)组成,每一域都需要去指定的数据类型。
ES中的数据类型:
1、简单类型
- 字符串
- text : 可以进行分词,不支持聚合
- keyword :不能进行分词,支持聚合
- 数值(类似java中的基本数据类型)
- 布尔类型:boolean
- 二进制:binary
- 范围类型
- integer_range, float_range, long_range, double_range, date_range
2、复杂类型
- 数组:[]
- 对象: {}
复杂类型在定义的时候可以不用指定,在插入数据的时候会自动进行创建。
8.2 映射的操作
添加映射
- 为已经创建的索引添加映射
1 | #添加映射 |
- 在创建索引的时候去指定映射
1 | #添加映射 |
查看映射
1 | GET person1/_mapping |
添加域
1 | #添加字段 |
9 文档操作
添加文档
- 指定id添加文档
1 | POST /person1/_doc/2 |
- 不指定id添加文档
1 | POST /person1/_doc/ |
获取文档
1 | # 获取id为1的文档 |
删除文档
1 | #删除指定id文档 |
10 分词器
10.1 概述
作用:就是对要存储的数据进行分词,并且在进行搜索的时候根据不同的搜索情况会对关键字进行分词。
在ES中其实提供了很多的分词器,但是这些分词器对中文的分词并不是特别的友好。当我们不指定分词器的情况下,默认使用的就是标准分词器(Standard Analyzer),对中文进行分
词的时候使用的是单字分词。
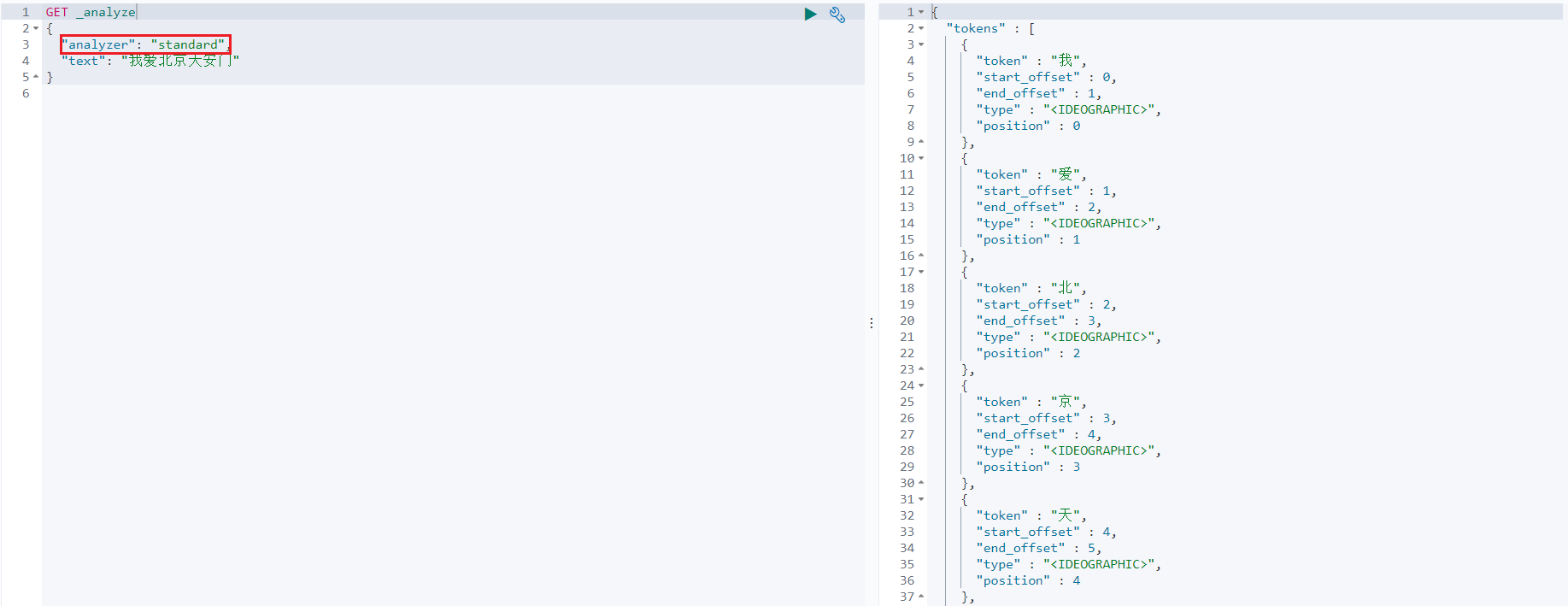
要想对中文进行分词,就需要去使用一些中文分词器。
10.2 IK分词器
安装ik分词器
1、把ik分词器下载下来
网址:https://github.com/medcl/elasticsearch-analysis-ik/
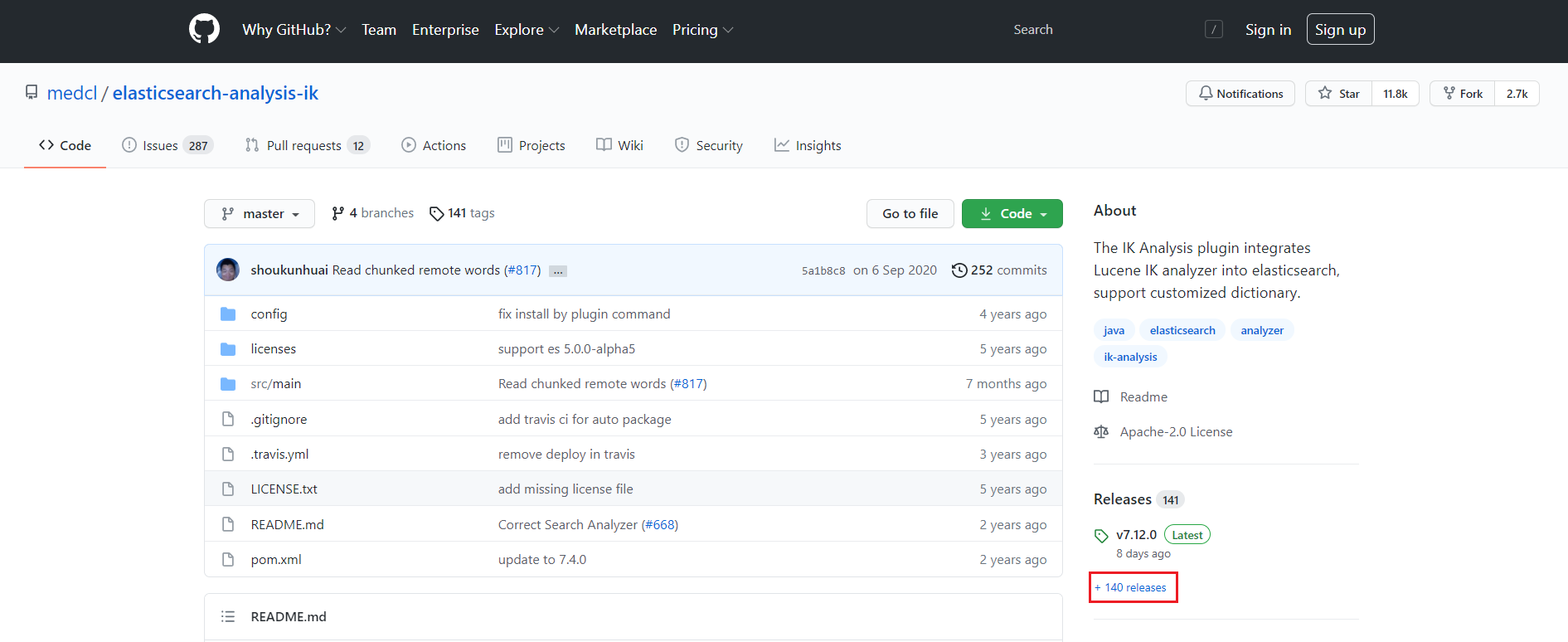
找到7.4.0版本的ik分词器:

下载下来以后就是一个:elasticsearch-analysis-ik-7.4.0.zip
2、对上述的压缩包进行解压
1 | 进入到es的插件目录 |

注意:需要重启es
测试IK分词器
IK分词器中提供了两种算法:
1、ik_max_word:细粒度分词(分的词比较多)
2、ik_smart:粗粒度分词(分的词比较少)
1 | #方式一ik_max_word |
问题1:这两种算法应该如何进行选择呢?
在进行数据存储的时候我们一般情况下选择的就是:ik_max_word
在进行搜索的时候我们一般情况下选择的就是:ik_smart
问题2:如何进行指定?

注意:在后期开发的时候,一般情况下不会去显示的指定分词算法,而使用的就是和存储数据时相同的分词算法。
基本搜索
1、termQuery:词条查询。特点:不会对搜索的关键字进行分词
1 | GET teacher/_search |
2、matchQuery:匹配查询。特点:会对搜索的关键字进行分词(分词算法取决于当时在创建索引的时候通过search_analyzer指定的分词算法,如果没有指定使用analyzer所指定的分
词算法)
1 | GET teacher/_search |
11 Java Api操作ES
11.1 Spring Boot整合ES
关于整合其实Spring官方也提供了对应起步依赖,但是使用这个起步依赖(spring-boot-starter-data-elasticsearch)中的API来操作ES并不是特别的方便。因此一般情况下不会去选择这
个起步依赖。而是使用ES官方所提供的API进行操作。
整合思想:导入ES官方所提供的API的依赖包,通过java配置的方式去配置客户端对象
pom.xml
1 | <!--引入es的坐标--> |
配置类:配置客户端对象RestHighLevelClient
1 |
|
11.2 操作索引
创建索引
1 |
|
查询索引
1 |
|
删除索引
1 | /** |
判断所以是否存在
1 |
|
11.3 文档操作
添加文档
1、基于Map的数据进行添加
1 |
|
2、基于Json的数据进行添加
1 |
|
修改文档
1、通过index方法进行修改(判断当前文档的id是否存在,如果不存在进行添加,如果存在进行修改)
2、通过update方法进行修改
1 |
|
获取文档
1 |
|
删除文档
1 |
|